How to Upgrade DOKS Clusters to Newer Versions
DigitalOcean Kubernetes (DOKS) is a managed Kubernetes service. Deploy Kubernetes clusters with a fully managed control plane, high availability, autoscaling, and native integration with DigitalOcean Load Balancers and volumes. DOKS clusters are compatible with standard Kubernetes toolchains and the DigitalOcean API and CLI.
You can upgrade DigitalOcean Kubernetes clusters to newer patch versions (for example, 1.20.1 to 1.20.2) as well as new minor versions (for example, 1.19.1 to 1.20.1) in the DigitalOcean Control Panel or in doctl, the command line interface (CLI) tool.
There are two ways to upgrade:
-
On demand. When an upgrade becomes available for DigitalOcean Kubernetes, you can manually trigger the upgrade process. You can upgrade to a new minor version using the manual process, provided you first perform all available patch-level upgrades for your current minor version.
-
Automatically. You can enable automatic upgrades for a cluster that happen within a maintenance window you specify. Automatic updates trigger on new patch versions of Kubernetes and new point releases of DigitalOcean Kubernetes subsystems with non-breaking updates. However, your cluster is not be automatically upgraded to new minor Kubernetes versions (for example, 1.19.1 to 1.20.1).
Required Upgrades
When a required upgrade is scheduled for your cluster, a notification appears in the control panel indicating the target version and when the required upgrade is scheduled to occur. You can configure the weekday and time required upgrades occur in the Upgrade window in the Settings tab of the cluster. You can upgrade the cluster yourself before this date.
When a minor version becomes unsupported, we schedule an upgrade to the latest patch version of the next supported minor version. We notify you via email 30 days prior to the scheduled upgrade. We notify you again 7 days and the day before the upgrade starts.
DigitalOcean may schedule an upgrade to the latest patch version of the cluster’s current minor version if a serious security vulnerability is identified in the version your cluster is running. We notify you at least 7 days before the upgrade, as well as the day before the upgrade starts.
DigitalOcean runs a cluster linter check before each required upgrade. A subset of the errors are included in the 30-day notice email and also appear in the control panel. If cluster linter errors are present, you must fix the issues.
The Upgrade Process
During an upgrade, the control plane (Kubernetes main) is replaced with a new control plane running the new version of Kubernetes. This process takes a few minutes, during which API access to the cluster is unavailable but workloads are not impacted.
Once the control plane is replaced, the worker nodes are replaced in a rolling fashion, one worker pool at a time. DOKS uses the following replacement process for the worker nodes:
-
Identify a number of nodes to drain.
-
Perform the following steps for each node concurrently:
a. Generate the list of pods running on it. This does not include DaemonSets or mirrored pods.
b. Mark the beginning of the drain start time as an annotation on the node. Eviction timeout is 15 minutes and drain (node deletion) timeout is 30 minutes.
c. Evict as many pods concurrently as the PodDisruptionBudget (PDB) policies allow. If the process hits the eviction timeout while draining a node, it switches to deleting the pods. If it hits the drain timeout while draining a node, it switches to deleting the node.
d. Wait a bit to allow for pod disruption budget to recover.
e. Repeat the above steps until all pods are drained.
As nodes are upgraded, workloads may experience downtime if there is no additional capacity to host the node’s workload during the replacement. If you enable surge upgrades, then up to 10 new nodes for a given node pool are created up front before the existing nodes of that node pool start getting drained. Since everything happens concurrently, one node stalling the drain process doesn’t stop the other nodes from proceeding. However, since one pool is upgraded at a time, it means that DOKS doesn’t move to the next node pool until the current node pool finishes. When you enable surge upgrades, Kubernetes reschedules each worker node’s workload, then replaces the node with a new node running the new version and reattaches any DigitalOcean Volumes Block Storage to the new nodes. The new worker nodes have new IP addresses.
Surge Upgrades
Surge upgrades create duplicate upgraded nodes, then drain the workloads from the old nodes to the new nodes, and finally remove the old nodes. Surge upgrades create up to 10 duplicate nodes. As a result, larger cluster nodes are upgraded 10 at a time.
Surge upgrades are available at no additional cost and are enabled by default when you create a new Kubernetes cluster. We recommend enabling surge upgrades when upgrading an existing cluster for a faster and more stable upgrade.
To enable surge upgrades, in the Surge upgrades section of the Settings tab of your cluster, click Edit. Select the Enable surge upgrades option and click Save.

To use surge upgrades for the entire upgrade duration, your Droplet limit must be at least n + min(10, num_nodes), where num_nodes is the number of nodes in your cluster and n is your current Droplet count. For example, if you have a 12-node cluster and 5 Droplets, your Droplet limit must at least be 15. You can request a Droplet limit increase at any time.
If an upgrade starts with less than the required number of Droplets or the limit is reached during the upgrade, then a partial upgrade is done using the available Droplets and the remaining upgrade happens without the surge enabled.
Upgrading via Control Panel
Upgrading On Demand
To update a cluster manually, visit the Overview tab of the cluster in the control panel. You see a View Available Upgrade button if there is a new version available for your cluster. Click this button to begin the upgrade process.
Once an upgrade starts, you can see its progress in the Overview and Resources tabs.
Upgrading to a New Minor Version
The on-demand process is required when upgrading your cluster to a new minor version of Kubernetes. During this process, you can run our cluster linter before upgrading. This automatically checks the cluster to ensure it’s conforming to some common best practices, and links to the fixes recommended in our documentation, to help mitigate issues that might affect your cluster’s compatibility with the newer version of Kubernetes. Click Run Linter on the upgrade modal to begin.
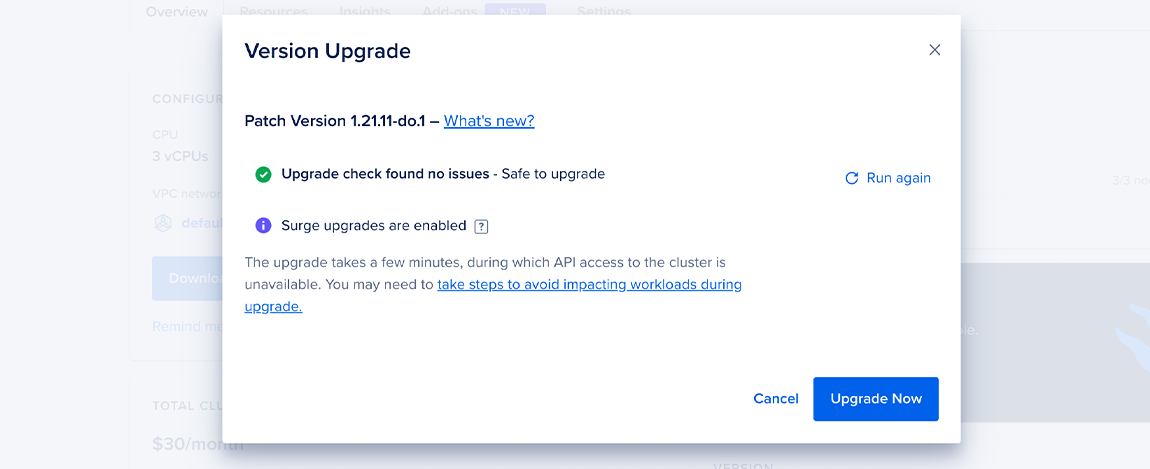
Upgrading to New Control Plane
DigitalOcean Kubernetes clusters originally created with version 1.20 or older have a version of the control plane architecture which does not allow you to enable high availability. However, you can now upgrade your control plane to the new version. This upgrade option is available for Kubernetes versions currently 1.22 and later.
In the cluster’s Overview page or the View Available Upgrade pop-up list, follow the upgrade process to get the new control plane.

The upgrade process may disrupt your cluster’s operations for up to approximately 2 minutes. This is because the upgrade involves a significant Cilium configuration change; so, during the migration, many worker nodes are on different configurations and therefore cannot communicate with each other until all the pods have rapidly restarted.
In addition to following the steps to minimize disruptions during upgrades, we recommend you do not create any new workloads during the upgrade. This includes creating new deployments and increasing replica count for existing processes manually or automatically (such as with replica-adjusting controllers like HPA).
Upgrading Automatically
To enable automatic upgrades for a cluster, visit the Settings tab of the cluster. In the Automatically upgrade minor version patches section, click the Automatically install minor version patches checkbox.
Automatic upgrades occur during a cluster’s 4-hour upgrade window. The default upgrade window is chosen by the DigitalOcean Kubernetes backend to guarantee an even workload across all maintenance windows for optimal processing.
You can specify a different maintenance window in the Settings tab of a cluster. In the Upgrade window section, click Edit to specify a different start time. Upgrade windows are made up of two parts: a time of day and, optionally, a day of the week. For example, you can set your upgrade window to 5 AM any day of the week or to 8 PM on Mondays.
You receive a notification email 30 days, 7 days, and 1 day before an automatic upgrade.
Even if you have auto upgrades enabled, you can still upgrade on-demand by clicking the View Available Upgrade button in the Overview tab.
Upgrade Using Automation
If you do not provide a version in the version field, the cluster upgrades to the next minor version of Kubernetes (for example, 1.28.1 to 1.29.1). You can retrieve a list of available version using the /v2/kubernetes/options endpoint or the doctl kubernetes options command.
Upgrading to a Specific Version
To upgrade to a specific Kubernetes version, rather than automatically upgrading to the latest version, you must first use your cluster ID to get a list of available upgrades for that cluster:
doctl kubernetes cluster get-upgrades <cluster-id>
Then, use the slug value returned by the get-upgrades call to perform the upgrade:
doctl kubernetes cluster upgrade <cluster-id> --version 1.20.2-do.0
Minimize Disruptions During Upgrades
Upgrading your cluster can cause disruptions in the availability of services running in your workloads. Consider the following measures to improve service availability during upgrades.
Configure a PodDisruptionBudget
A PodDisruptionBudget (PDB) specifies the minimum number of replicas that an application can tolerate during a voluntary disruption, relative to how many it is intended to have. For example, if you set the replicas value for a deployment to 5, and set the PDB to 1, potentially disruptive actions like cluster upgrades and resizes occur with no fewer than four pods running.
For more information, see Specifying a Disruption Budget for your Application in the Kubernetes documentation.
Implement Graceful Shutdowns
Ensure that the containers in your workload respond to shutdown requests in a way that doesn’t suddenly destroy service. You can use tools like a preStop hook that responds to a scheduled Pod shutdown, and specify a grace period other than the 30-second default.
This is important because cluster upgrades results in Pod shutdowns, which follow the standard Kubernetes termination lifecycle:
- The Pod is set to the “Terminating” state and removed as an endpoint.
- The
preStophook is executed, if it exists. - A SIGTERM signal is sent to the Pod, notifying the containers that they are going to be shut down soon. Your code should listen for this event and start shutting down at this point.
- Kubernetes waits for a grace period to pass; the default grace period is 30 seconds.
- A SIGKILL signal is sent to any containers that still haven’t shut down, and the Pod is removed.
For more information, see Termination of Pods in the Kubernetes documentation.
Set up Readiness Probes
Readiness probes are useful if applications are running but not able to serve traffic, due to things like external services that are still starting up, loading of large data sets, etc. You can configure a readiness probe to report such a status. Think of a command that you could execute in the container every few seconds that would indicate readiness if it returns 0, and specify the command and the schedule in your Pod spec.
For more information, see Configure Liveness, Readiness and Startup Probes in the Kubernetes Documentation.