Monitoring Metrics
DigitalOcean Monitoring is a free, opt-in service that gathers and displays metrics about Droplet-level resource utilization. Monitoring supports configurable alert policies with integrated email and Slack notifications to help you track the operational health of your infrastructure.
DigitalOcean Monitoring uses a variety of metrics to track system health. This glossary covers the different system resources tracked, the units used to measure them, and how they are represented by DigitalOcean Monitoring.
In computing, a metric is a standard for measuring a computer resource. Metrics can either refer to the resource and unit with which to measure, or the data that is collected about that resource.
CPU Utilization
CPU utilization measures the amount of processor being used at a given time. CPU utilization is expressed as a percentage.
In the Droplet graphs, CPU usage is broken down based on Linux’s conception of system and user time. System time is time spent executing kernel-level instructions, while user time is time spent executing user space instructions, which is defined by anything outside of the kernel. Alert policies do not distinguish between user and system time.
On DigitalOcean, total use of all processors combined is indicated by 100%. This differs from some CPU usage tools which report 100% per CPU or core. For example, other tools might express metrics out of 200% on a machine with two CPUs, or 400% for a quad-core processor.
Load Average
Load average is a measure of processor load, expressed as the exponentially weighted moving average of processes that are using CPU plus those waiting for CPU time. An exponentially weighted moving average means that older data points are given exponentially less weight in the average calculation. In other words, more recent data points are more impactful in the average calculation.
The metrics agent collects information for 1-, 5-, and 15-minute load averages, which come from /proc/loadavg.
Load averages do not take the number of cores, or Droplet vCPUs, into consideration. On a single vCPU Droplet, a load average of 2.0 means that the processor is operating over capacity, with 1 process using vCPU and 1 waiting on average. On a 4 vCPU Droplet, that same load average would equate to 50% of maximum load; on average, 2 processors are each busy with one process, and 2 are free.
As general rule, if the 15-minute load average is trending above the number of vCPUs, we recommend looking into it right away. Occasional spikes in the 1- and 5-minute load averages above the number of vCPUs are typically acceptable.
Memory
Memory utilization is a measurement of the memory being consumed on the server. This is expressed as a percentage of the total available physical memory:
DigitalOcean calculates memory consumption by evaluating memory information exposed in /proc/meminfo.
Linux borrows unused memory for disk caching to optimize performance, but this memory can be given back immediately if needed by a process. Because cache memory is temporarily on loan, DigitalOcean does not report memory used for caching as used memory. On DigitalOcean, used memory is calculated by subtracting free memory and memory used for caching from the total memory amount. Other utilities like htop and top, however, may include cache as used memory.
Disk I/O
Disk I/O, or input/output, is a measure of how much read and write activity the server’s disks are experiencing. This is expressed in MB/s, or megabytes per second.
DigitalOcean breaks disk I/O down into read and write operations, which are handled separately. Droplet graphs show these as two separate lines within the Disk I/O graph:
Separate alert policies can be created to monitor disk read operations and disk write operations.
Disk Usage
Disk usage is a measurement of how much disk space is currently being used. This is expressed as a percentage of the total disk space available on the server.
This value takes into account the Droplet’s root storage and any additional attached block storage devices. The values of each storage device are rolled up into a single value that represents the total storage space of the server:
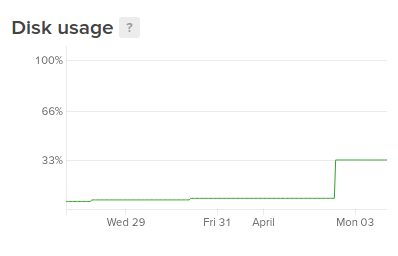
Alert policies are also interpreted in total disk space.
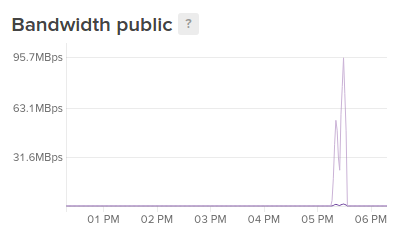
Bandwidth
Bandwidth is a measurement of the amount of incoming or outgoing traffic passing through the Droplet’s network interfaces. This is expressed in Mbps, or Megabits per second.
In Droplet graphs, bandwidth is broken down between public and private traffic. Public bandwidth is bandwidth over the public interface that connects to the internet. Incoming traffic is represented by one line, and outgoing traffic by another.
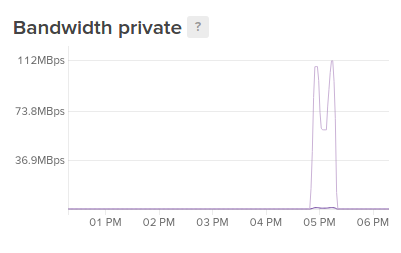
Private bandwidth is a measure of the traffic on the private interface that allows for communication within a datacenter. This graph will only be displayed if private networking is enabled and the interface has experienced traffic. Again, there are separate lines for incoming and outgoing traffic.
In alert policies, there is no distinction between public and private interfaces, but the separation of inbound and outbound traffic remains. An alert policy can track incoming traffic or outgoing traffic. Alerts policies are also defined in Mbps.