Workflows automate machine learning tasks, combining GPU instances with an expressive syntax to generate production-ready machine learning pipelines with a few lines of code.
Datasets referenced in the workflows spec need to be created before running the workflow for the first time. On subsequent runs of the workflow the dataset is reused, but this creates different Dataset versions for each output Dataset.
For more information about Datasets see Versioned Data.
The above Workflow creates a new output Dataset version in the Dataset named demo-dataset. So before running this Workflow make sure a Dataset with that name already exists. You can run this command to list your Datasets: gradient datasets list.
If you are not accustomed to creating datasets, we recommend our Workflows Tutorial. You can also brush up on datasets by visiting how to create a dataset and dataset version in the GUI.
Here is the short way to create a dataset. First, get a list of storage providers that are already part of your account. You should have at least one called Gradient Managed.
gradient storageProviders list
+------------------+-----------------+------+------------------------------------------+
| Name | ID | Type | Config |
+------------------+-----------------+------+------------------------------------------+
| Gradient Managed | splXXXXXXXXXXXX | s3 | accessKey: XXXXXXXXXXXXXXXXXXXX |
| | | | bucket: XXXXXXXXX |
| | | | endpoint: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX |
| | | | secretAccessKey: ******** |
+------------------+-----------------+------+------------------------------------------+
Then, create a dataset named demo-dataset using the Gradient Managed storage provider ID:
gradient datasets create \
--name demo-dataset \
--storageProviderId splXXXXXXXXXXXX
Datasets with other names can be created similarly. The dataset name should match the name referred to in the YAML. Datasets can also be referred to directly by their IDs, but names are usually more convenient, unless a specific Dataset version needs to be referenced.
To create a new dataset (one that does not yet have an ID) in the GUI, go to the Data tab in your team’s page and click “Create a Dataset”. This brings up a window to give it a name, optional description, and select the storage provider to create it on.
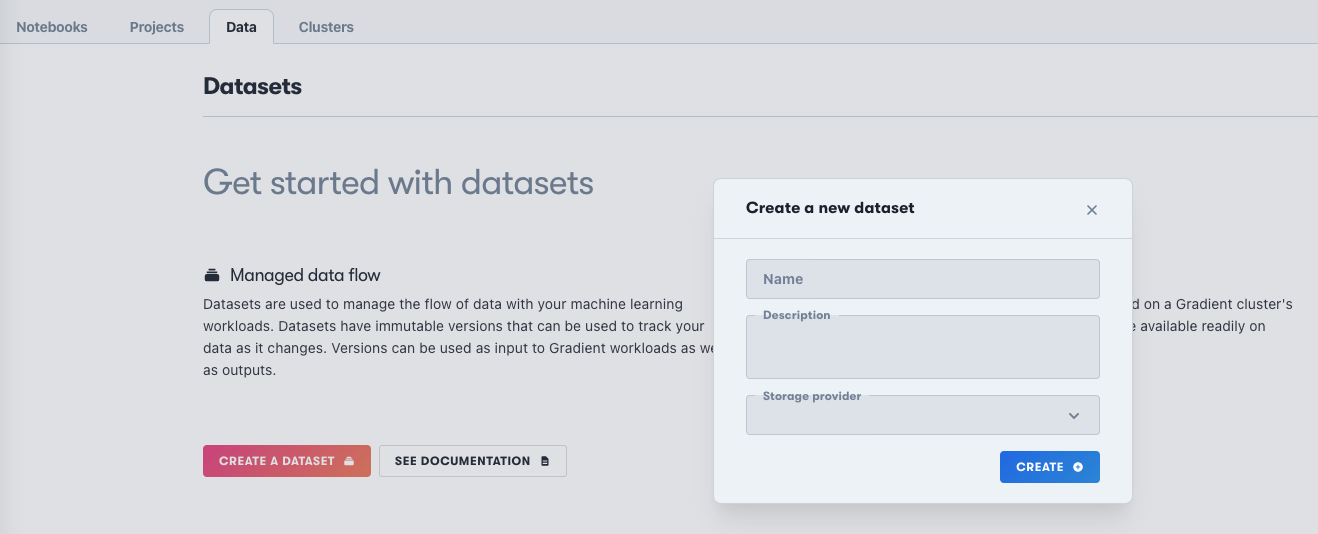
If the team already has datasets, there is a similar Add button. The resulting screen after creation allows you to upload files, or you can retrieve the dataset ID for use elsewhere.
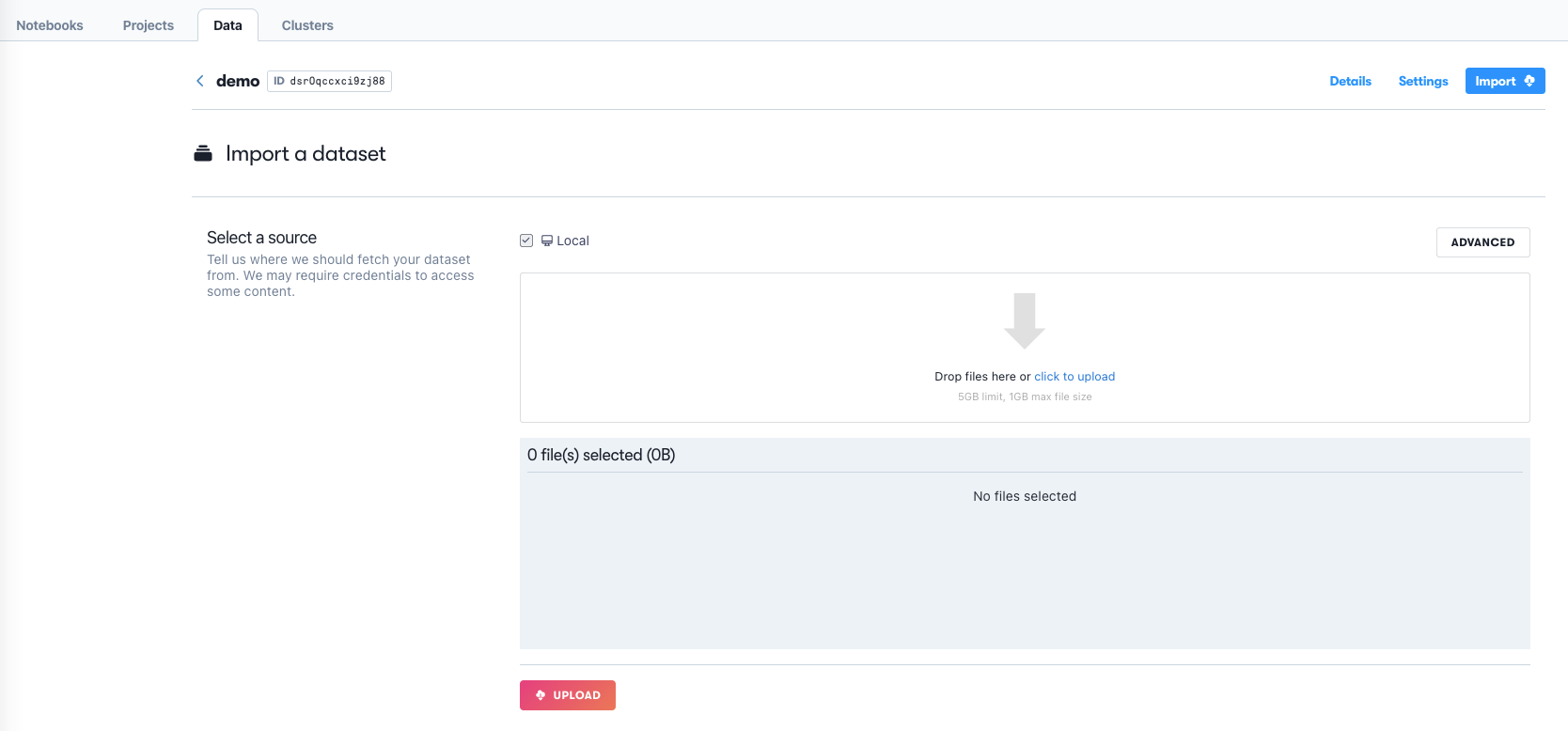
Importing data, or adding it in some other way such as a Workflow output, creates a new version of the dataset.
Datasets can also be created from the Notebook IDE through the Datasets tab.